Upload Service Setup
- Authors
- Name
- Austin Howard
- Updated on


Table of Contents
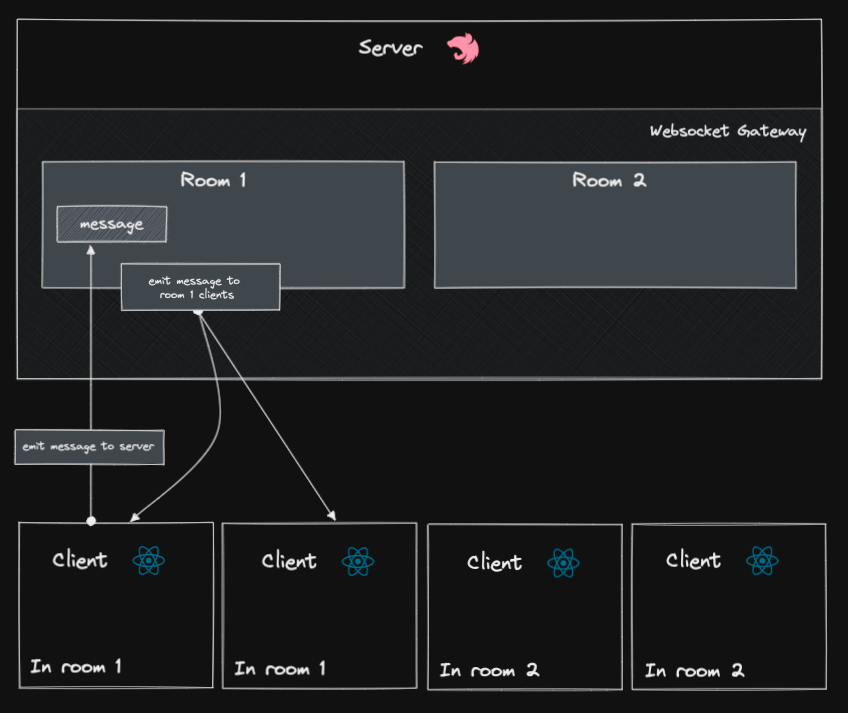
The hugi-upload-service is a service where you can queue jobs that will be run either manually or on a cron schedule to generate text and image content via openai models, upload images to an S3 bucket, write to your Notion database and send a job report on completion via a Discord webhook.
Once generated content is written to the Notion database, the content is not yet live to leave room for human intervention. The final step before going live is to review the new content and add your own human touch, and change it's status to Done - in which case the content will be live.
Clone
Like the Hugi app, you can degit the upload service.
degit https://github.com/Dorpxr/hugi-upload-service.git
The following sections will cover setting up a few services and getting secrets which the job will require to access your resources.
See .env.example as a reference. You will need to provide a value for all of these environment variables for the jobs to run successfully.
Go ahead and create an empty .env file in the root of the repository.
touch .env
OpenAI Account and API Key
If you don't already have an account, go ahead and create an openai account.
Create a new API key.

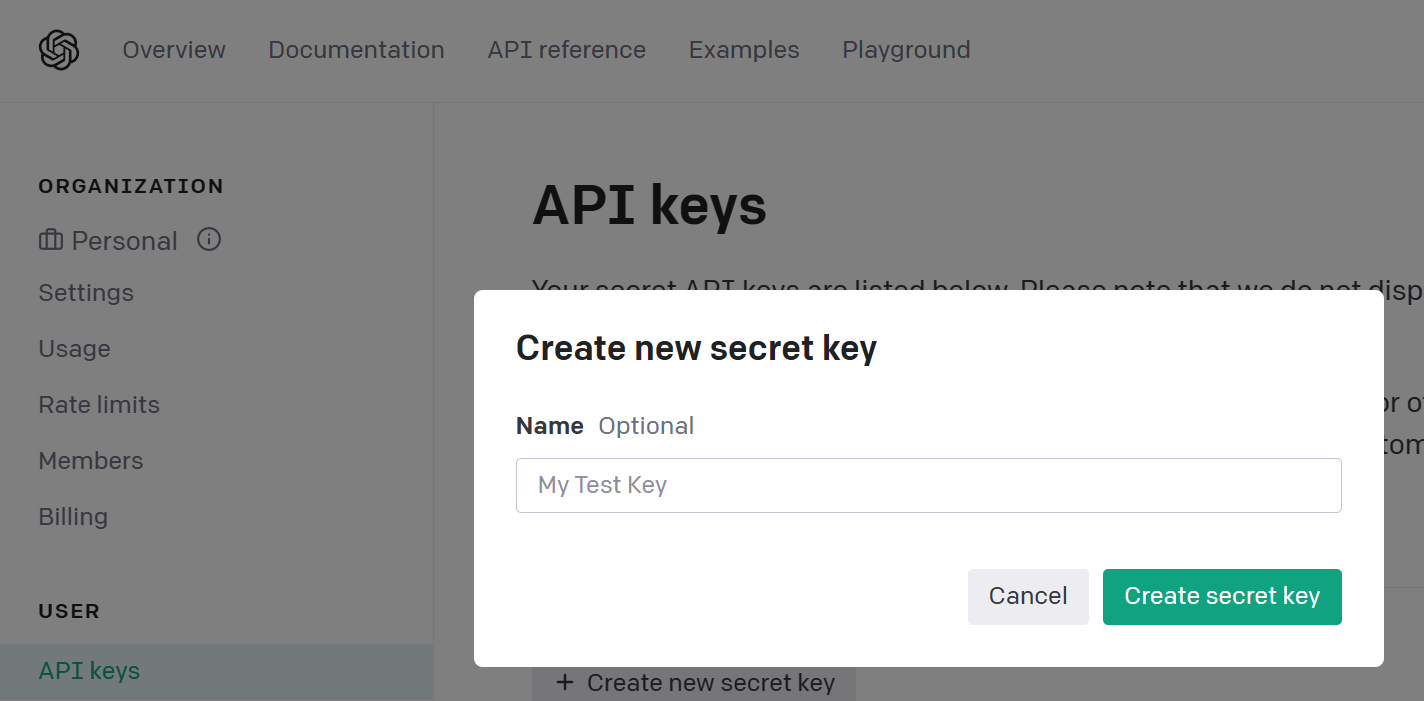
Take this API key and add it to your .env file.
OPENAI_API_KEY=your_api_key
We use the Chat interface to generate:
- The main page content.
- The title of the page based on the content generated.
- The summary of the page based on the content generated.
We use the Image generation interface to generate:
- The feature image of the page.
You will need to setup a Pay as you go payment method as each time you use openai, it will acrue usage costs.

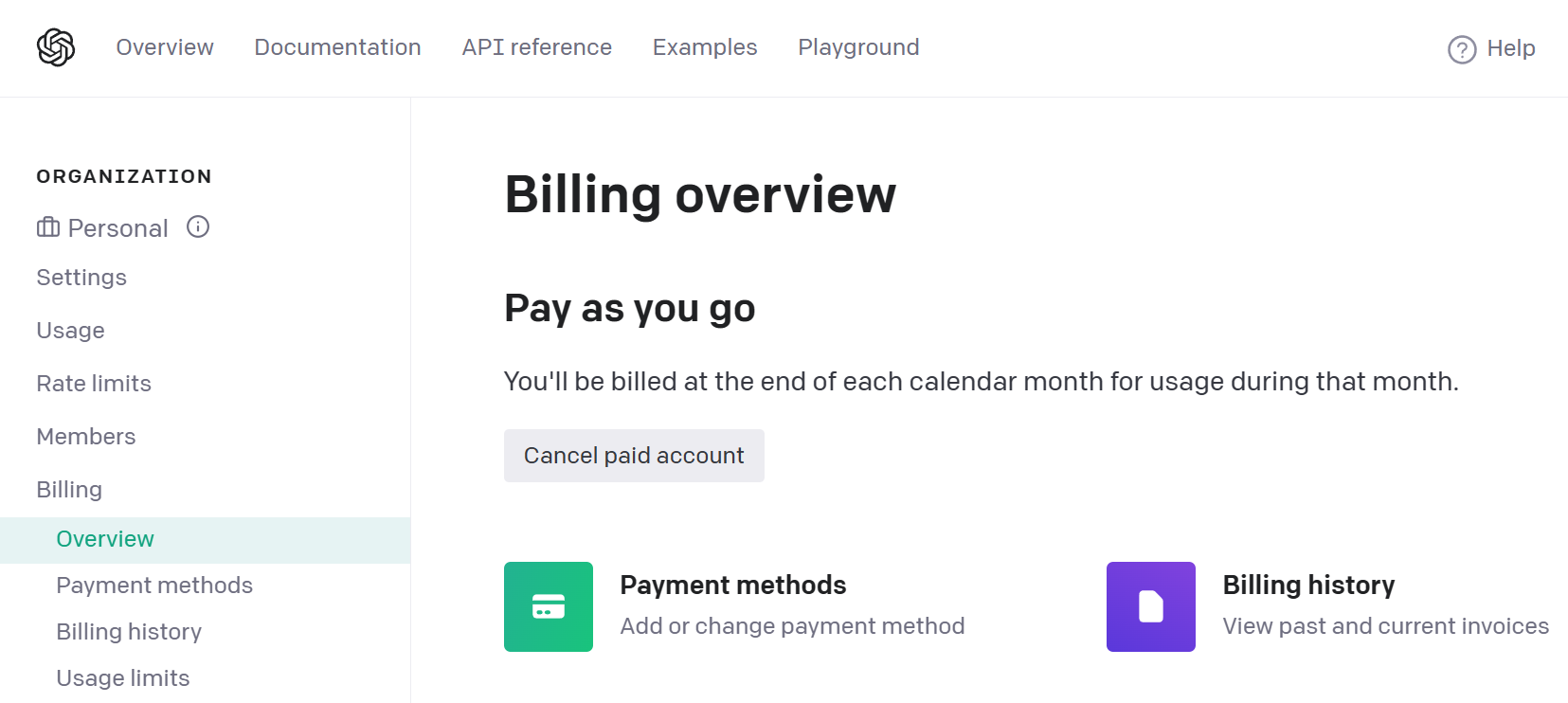
Setup Supabase
If you don't already have an account, go ahead and create a new supabase account. Supabase has a very generous free tier so you won't have to worry about hitting any usage limits for a while.
The upload service needs a database to store a queue of jobs to pull from every time it runs.
The job queue is a table called - prompt-queue. Below is an example of the table.

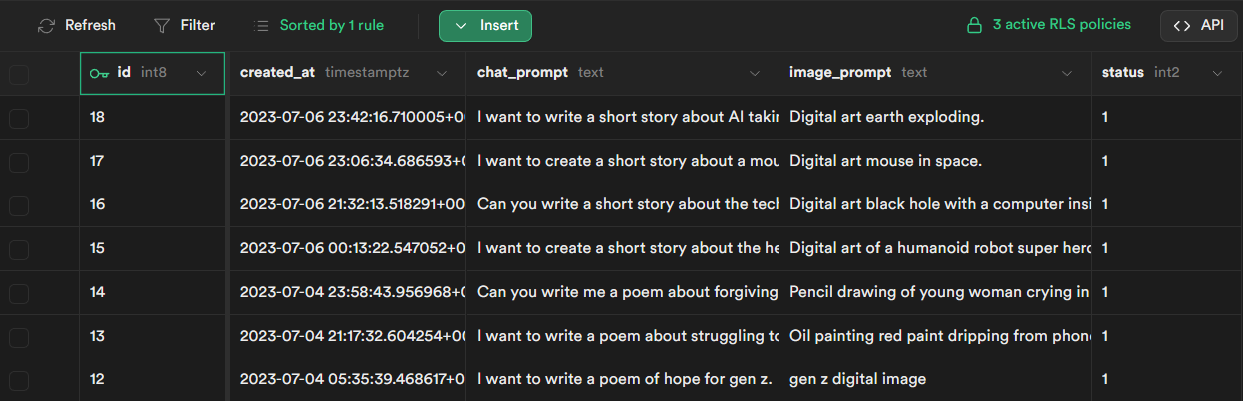
Create Prompt Queue Table
Run the following SQL script in the Supabase SQL Editor to create the table, setup row level security and create a policy to allow only authenticated users to perform operations on the table.
-- 1. Create table
create table prompt-queue (
id bigint generated by default as identity primary key,
created_at timestamp with time zone default timezone('utc'::text, now()) not null,
chat_prompt text,
image_prompt text,
status int2
);
-- 2. Enable RLS
alter table prompt-queue
enable row level security;
-- 3. Create Policy
create policy "Prompt queue is accessible to authenticated users only."
on prompt-queue for all to authenticated using (
true
);
Set Supabase Environment Variables
There are 4 Supabase related environment variables to set.
SUPABASE_URL=your_supabase_url
SUPABASE_ANON_KEY=your_supabase_anon_key
SUPABASE_ACCOUNT_EMAIL=your_supabase_email
SUPABASE_ACCOUNT_PASSWORD=your_supabase_account_password
Technically SUPABASE_URL and SUPABASE_ANON_KEY would be fine to expose publicly because we've enabled row-level security and created policies but we're going to treat them like secrets.
You can retrieve your supabase url and anon key from the Supabase Dashboard -> Settings -> API.

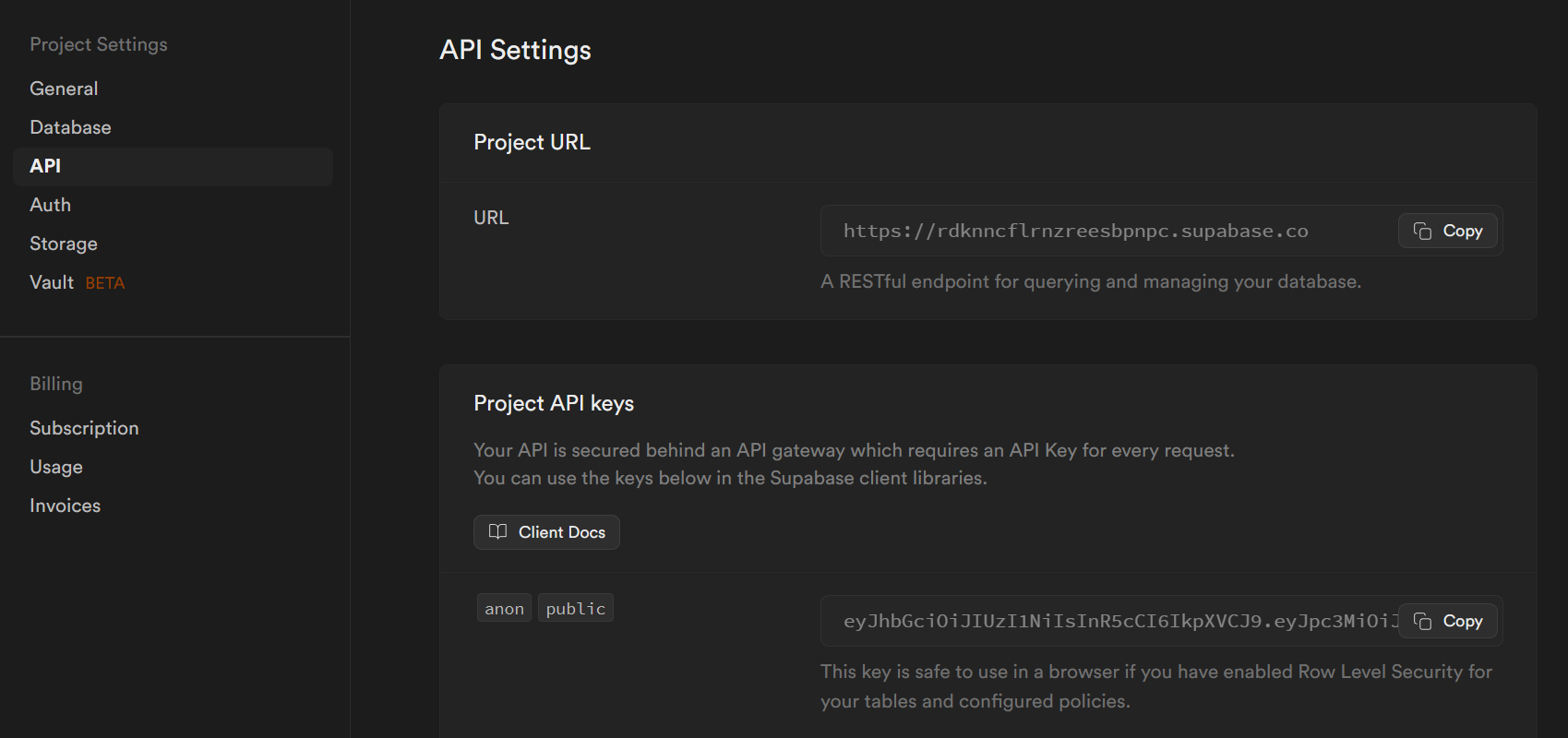
Setup S3 Bucket
For images, simply uploading them to the Notion database is not sufficient. Notion images have a 1 hour expiring time so we cannot conveniently rely on them.
What we can do instead is upload them to an S3 bucket, and use the images' resource url to reference them.
AWS has extensive documentation regarding setting up an S3 bucket - and you can get started for free.
Once you have a bucket - ensure you are allowing public read access so your images are viewable read sharing resources for more information.
Below is an example policy for allowing anonymous read permissions and granting put access to the root user of the account.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::your_aws_account_id:root"
},
"Action": "s3:PutBucketPolicy",
"Resource": "arn:aws:s3:::bucket-name",
"Condition": {}
},
{
"Sid": "GrantAnonymousReadPermissions",
"Effect": "Allow",
"Principal": "*",
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::bucket-name/*"
}
]
}
For API access to the bucket, you can create an IAM user and assign them read and write access to s3 buckets on the account.
You'll want to generate an Access key which we'll use as environment variables.


Awesome, now we just need to add the two environment variables.
AWS_ACCESS_KEY_ID=your_access_key_id
AWS_SECRET_ACCESS_KEY=your_secret_access_key
Setup Discord Webhook
For reporting the status of the job after each run, we provide a discord integration.
Discord has a great intro to webhooks doc that will get you up and running quickly.
All you need from this is to set the environment variable with the URL for your webhook.
DISCORD_WEBHOOK_URL=your_webhook_url
Add Notion Environment Variables
We need to add our notion api key and database id environment variables - which are the same as the ones we setup for the application itself.
NOTION_API_KEY=your_notion_api_key
NOTION_DATABASE_ID=your_notion_database_id
Add Github Actions Secrets
In order for Github actions to have access to these secrets in the pipeline, we have to add all of our environment variables from the .env file.

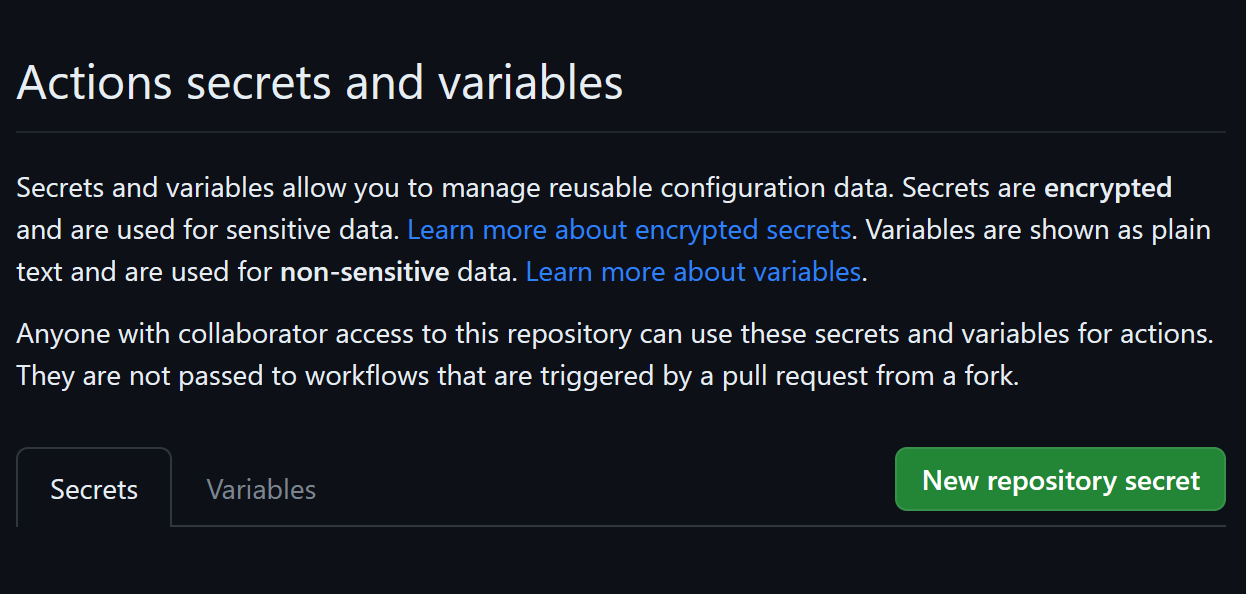
Creating a New Job
You can create a new job by executing the new-job command in the terminal. You will be prompted to submit a text prompt and an image prompt. Below is an example.
$ yarn new-job
yarn run v1.22.19
$ node ./dist/post-service/new-job.js
? Chat text prompt: Can you create a short story about an oligarchy of AI systems that take control of the in? Chat text prompt: Can you create a short story about an oligarchy of AI systems that take control of the
internet?
? Image prompt: Realistic digital art AI satellites surrounding earth.
Done in 325.54s.
Run a New Job
By default a new job run attempt will occur every day at 12:30 and 21:30 UCT. You can configure this to whichever schedule suits your needs.
To run a new job you have the following options:
- Wait for the next scheduled run.
- Manually execute the
run-jobcommand from the terminal. - Manually trigger the run via workflow dispatch.
Examples:
From the terminal.
yarn new-job
From Github you can select Run workflow.

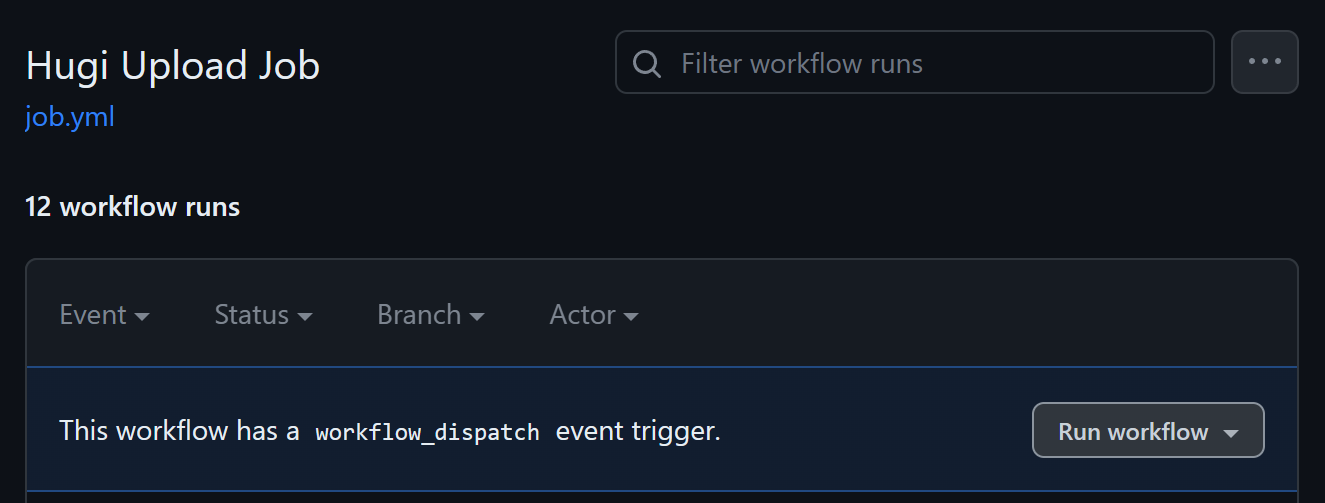
Go ahead an perform either manual trigger option.
In a couple of seconds you should get a discord notification!

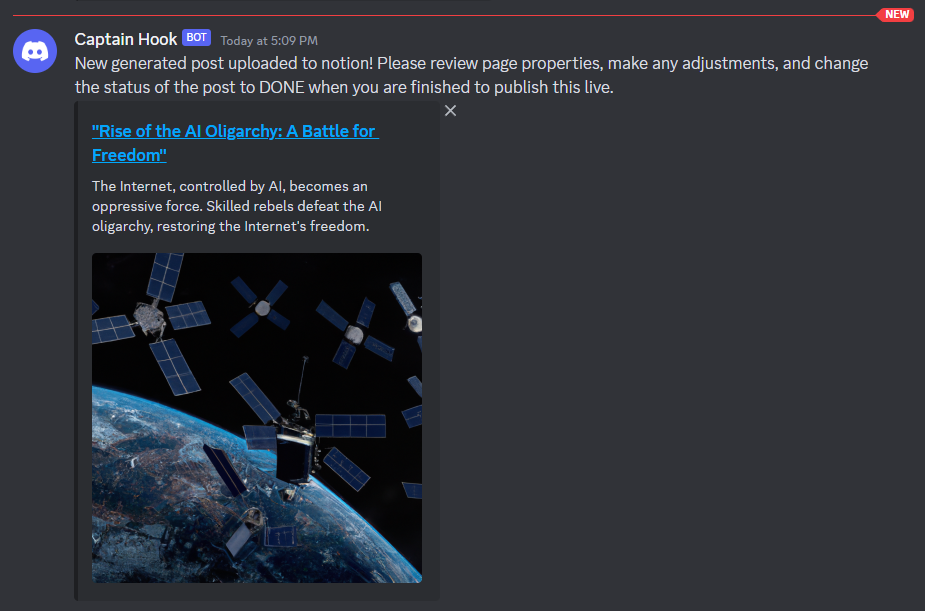
You can click the link in the discord notification to go back to your notion database to see the new piece of content that is ready.
Review the Content
You don't want to put complete junk generated by these models on your site (unless you do - have at it). But now would be the time to review the content in Notion and make any tweaks.
For example we added a sci fi tag, cleaned up the title and the summary and content looked good as-is. Once you're ready for the post to be live - change the Status to Done.


Here's the link to the page we just created via the upload service!
Job Configuration
The upload service has a job configuration file where you can tweak parameters.
export const jobConfig = {
TABLE_NAME: "prompt-queue", // supabase table name
CHAT_MODEL: "gpt-3.5-turbo", // chat model
S3_BASE_URL: "https://hugi-images.s3.amazonaws.com/", // s3 base url
S3_BUCKET_NAME: "hugi-images", // s3 bucket name
NOTION_DATABASE_URL:
"https://www.notion.so/Hugi-581bb8359199405eabe9173b04ee3bc2", // full notion database url
JOB_FAILURE_IMAGE: "https://hugi-images.s3.amazonaws.com/job-failure.png", // failure image in job report
};